Tools and Services for supporting the construction of the GRSF Knowledge Base¶
The main purpose of the Global Record of Stocks and Fisheries Knowledge Base (GRSF-KB) is to act as a central point where information about stocks and fisheries - derived from different sources - can be found. More specifically information from FIRMS, RAM legacy database and FishSource will be integrated into a semantic warehouse using semantic web technologies. To this end we are going to exploit top level ontologies (a more detailed description about the modeling activities can be found at GRSF_KB_modeling).
After its construction the knowledge base will be used for constructing the approved data in the registry in the form of stocks and fisheries records. Finally the contents of the registry will be exposed using a set of particular services. The following figure shows these steps.
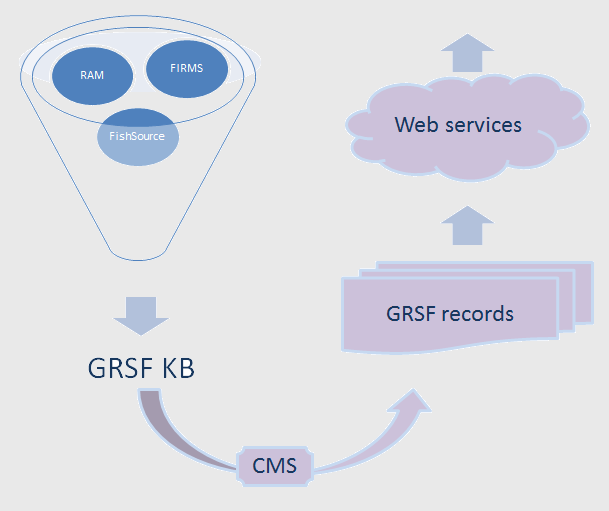
In this wiki page we discuss about the requirements and the technical solutions towards the construction and maintenance of the knowledge base.
Requirements¶
The administrator should be able to initiate the process of the construction of the GRSF knowledge base from the GRSF VRE, as well as to inspect the results. It is also important that he has the control of choosing whether he wants to reconstruct the entire knowledge base or only a part of it.
After the construction of the knowledge base, the user should be able to inspect specific stocks (or fisheries) and if the information they contain are correct approve them or reject them. This means that all the records in the knowledge base have an initial flag set to pending, which can be afterwards be changed to either approved or rejected. Furthermore the user will be able to annotate particular records (i.e. describing why a record has been rejected or wrong values).
Tools and Services¶
In general we will need two families of components; one for the construction of the GRSF KB, and one for the exploitation of the GRSF KB and for exposing its contents as well as for updating certain parts of it.
Construction and maintenance of GRSF KB¶
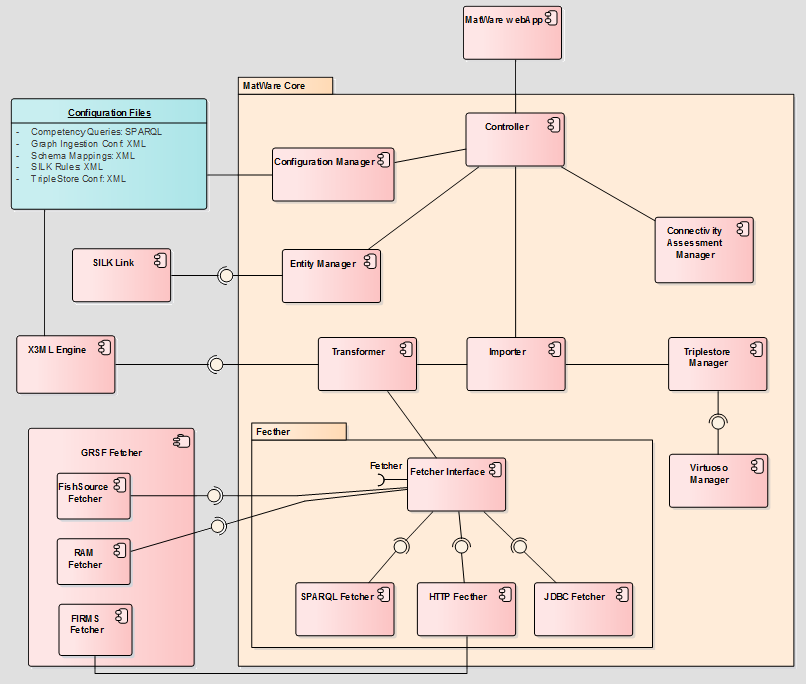
For the construction of the knowledge base we are going to use MatWare. MatWare is framework that automates the process of constructing semantic warehouses. We use the term semantic warehouse to refer to a read-only set of RDF triples fetched (and transformed) from different sources that aims at serving a particular set of query requirements. MatWare automatically fetches contents from the underlying sources using several access methods (SPARQL endpoints, HTTP accessible files, JDBC). The fetched data are stored (in their original form or after transforming them) in a RDF triplestore. To tackle the provenance requirements, several levels are supported: (a) at URIs and values level, (b) at triple level (separate graphspaces) and (c) at query level. MatWare also supports the refreshing of the warehouse by replacing specific sources as they evolve (instead of reconstructing the whole warehouse from scratch).
MatWare has been designed and developed by FORTH. It's license is restricted so that the source code cannot be shared outside FORTH, however the pre-compiled binary packages (the executable files) can be disseminated to other parties, by signing a mutual agreement (where the purpose and the duration have to be specified). A bilateral agreement has already been singed by FORTH and CNR (starting from 12/05/2016 until 01/03/2020).
MatWare is delivered as a software library that can be configured through a configuration file (in XML format). To assist users exploiting MatWare a front-end web application will be developed. The web application will have the following capabilities:
- configuring the triplestore that will be used (i.e. the connectivity details)
- review and update the (schema) mappings between the schemata of the underlying sources and the top level ontology
- change the details as regards the fetching and downloading of the data from the underlying sources
- modify the instance matching rules (SILK rules)
- determine the running mode (i.e. reconstruct the knowledge base or refresh only a part of it)
- inspect the results in terms of connectivity metrics
A possible architecture for the above deployment is shown in the following component diagram. The diagram shows that MatWare framework actually depends on a number of different external configuration files. The main functionality of MatWare webApp is to be able to access and update these configuration files and trigger MatWare though the Controller class.
Exploiting the GRSF KB¶
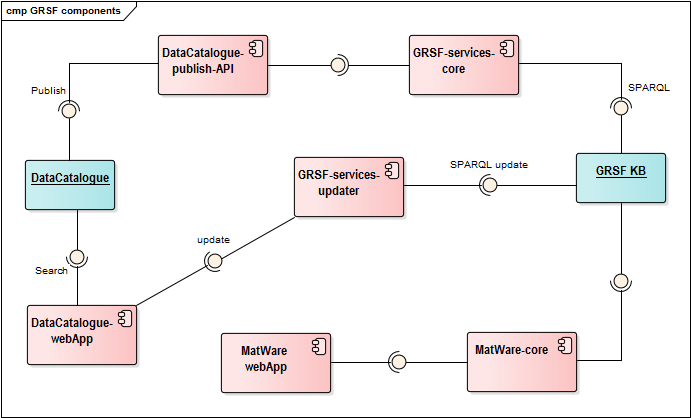
For exploiting the GRSF knowledge base the component GRSF-services-core will be developed; it will be a library that will contain the appropriate methods for retrieving the contents from the knowledge base. The contents of the knowledge base will be a set of RDF triples, therefore the library will act as an abstraction layer and will be able to formulate the appropriate queries for retrieving information from the knowledge base and present them to the user as single units (i.e. GRSF records).
Apart from exposing the GRSF KB contents as single units the GRSF-services-core component will be able to update particular information in the GRSF KB. More specifically it will allow uses approve, reject or annotate specific records, by updating the corresponding graphs of the GRSF KB.
Since GRSF-services-core is just a library offering the core functionalities for exposing the contents of the GRSF KB and updating them, it is required to have a component that will offer a graphical user interface and will allow the desired interaction with the user. One approach it to handle each record as a dataset and reuse the DataCatalogue facilities. The DataCatalogue uses its own database for storing dataset information (i.e. metadata). Practically this means that for exploiting the contents of the GRSF KB we should first publish them to the DataCatalogue by using the appropriate libraries. The following component diagram shows how the various components are connected for offering the aforementioned functionalities.
Furthermore two sequence diagrams depicting these functionalities and the sequential steps and the components that are exploited are given in the bottom of this page.
Data Catalogue publishing facilities accept JSON objects, therefore it is required to transform GRSF records to JSON format before ingesting them in the data catalogue. An indicative list of such JSON objects is given at the bottom of this wiki page.
Activities and effort breakdown (tentative)¶
| Activity Title | Short Description | Estimated/Consumed Effort | Status | Partners involved | Relevant Issue |
|---|---|---|---|---|---|
| Sources Analysis | This task comprises the analysis of the schemata and the contents of the underlying sources that contain information about stocks and fisheries. More specifically these sources are: FIRMS, RAM Legacy Database and FishSource | ~2/3 PMs | Completed | FORTH, FAO | #3398 |
| Mappings Definition | This task contains the definitions of the mappings for transforming the data from the original schemata to the target schema (i.e. with respect to MarineTLO). | ~3/1 PMs | Ongoing | FORTH | #3400 |
| MatWare-core | This task will lead to the integration of X3ML engine with MatWare to support the configurability of the mappings between source schemata and target schemata | ~1/1 PMs | Completed | FORTH | #1806 |
| MatWare-plugins | This task will lead to the development of the required plugins for fetching data from the underlying sources | ~1/1 PMs | Completed | FORTH | #3926 |
| Inventory of triplestores | This task is responsible for identifying currently existing solutions as regards triplestores with emphasis on their scalability. | ~1/0 PMs | Not stated yet | FORTH | |
| Construction of the GRSF Knowledge Base | This tasks contains the construction of the knowledge base and the merging of similar concepts coming from different sources | ~3/0 PMs | Not started yet | FORTH | |
| MatWare front-end | This task will lead to the creation of a web application acting as a front end for configuring MatWare. | ~2/0 PMs | Ongoing | FORTH | #4994 |
| GRSF-services-core (NEW) | This task is responsible for exposing and updating the contents of GRSF KB. | ~2/0 PMs | Ongoing | FORTH | |
| DataCatalogue publishing | This task is responsible for organizing the activities that will publish the contents of the GRSF-KB to the DataCatalogue. | ? PMs | Not started Yet | FORTH, CNR, FAO | |
| GRSF-KB updates | This task is responsible for organizing the activities that will support the updating of particular fields of the GRSF KB (i.e. approval, rejection, annotation) . | ? PMs | Not started Yet | FORTH, CNR, FAO |
Refreshing the GRSF KB¶
GRSF Knowledge Base is refreshed through new data harvest. The refreshed content is first published in GRSF PRE VRE (https://blue-cloud.d4science.org/group/grsf_pre/grsf_pre).
After a revision of the published records, the GRSF team decide to update the "official" GRSF VREs with the new contents.
The refresh workflow consists of the following steps:
- Export published information to be preserved from the current version of GRSF KB.
- Remove all records from the GRSF Admin VRE and GRSF Public VRE catalogs
- Purge the contents of the current version of GRSF KB
- Ingest the already transformed newly harvested records from the GRSF data sources (i.e. FIRMS, RAM, FishSource) in the new version of GRSF KB using information from the older version of KB (e.g. UUIDs, URLs, etc.)
- Construct and ingest GRSF records using using information from the older version of KB (e.g. UUIDs, status, etc.)
- Calculate similarities based on GRSF rules (e.g. geo proximities, species, genus, etc.)
- Publish records in GRSF Admin VRE and GRSF Public VRE catalogs
The Publishing workflow of new data consists in the following steps.
- Data harvest from the Source databases
- Transformation of harvested resources.
- Construction of GRSF KB using the transformed records. During this process, a set of obsolete records will be identified. They refer to "legacy" records that exist in the previous version of the GRSF KB, but are not amongst the new harvested resources. Obsolete "Legacy" records will be provided to data source providers for examination.
- Construction of GRSF records using the previous version of GRSF KB. During this process, a set of obsolete records will be identified. Obsolete GRSF records refer to records that were publicly available in the previous version of the GRSF KB (i.e. the ones with status approved). Obsolete "GRSF" records will be provided to data source providers for examination.
- Publish all records in GRSF Pre
- Publish all records in GRSF Admin and the public ones in GRSF Public (after reviewing them in GRSF Pre).

