GRSF Maintenance¶
- Table of contents
- GRSF Maintenance
In this page we will describe the maintenance activities for GRSF.
High-Level Architecture¶
To construct and expose GRSF, a set of different software components and technologies are being exploited.
The following diagram depicts a high-level overview of the different components that are used, as well as their interactions for delivering GRSF to end-users.
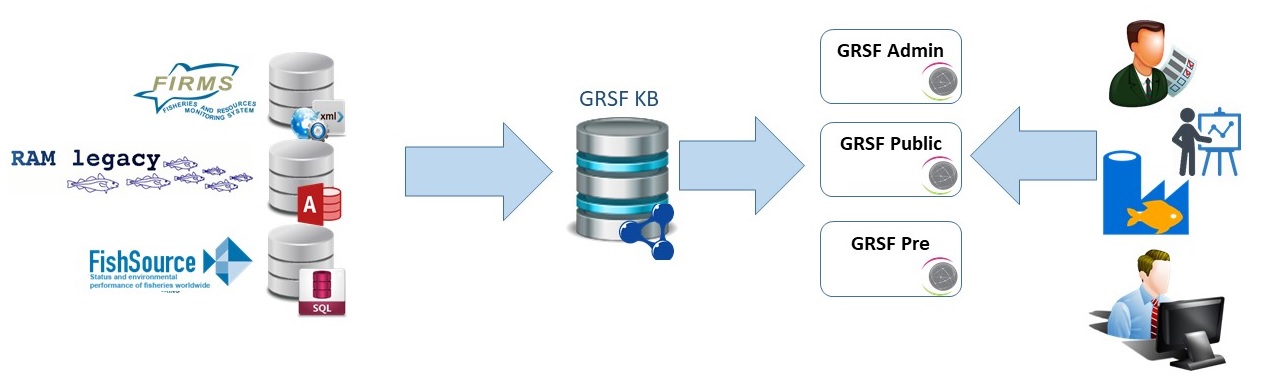
GRSF Knowledge Base (GRSF KB), is the core part of the entire architecture. It is a semantic warehouse, that integrates information coming from the original data sources. For this reason, a set of tools are used to harvest, normalize and transform those data w.r.t. an extended version of the top-level ontology MarineTLO. GRSF KB acts as the glue that interconnects information coming from different data sources and constructs a knowledge graph. The main advantage is that is allows answering complex queries, that are very difficult (or in some cases impossible) to answer by relying solely on each single data source. After GRSF KB is populated with information about stocks and fisheries, then a dedicated software component (grsf-services-core) fetches information from the knowledge graph and constructs the so-called stock and fishery (legacy) records. At this stage, each legacy record corresponds to their equivalent records in the original data source. A detailed discussion about GRSF records, their attributes and the corresponding rules can be found at GRSF database overview The same component is being used to generate GRSF Stock and GRSF Fishery records. Each GRSF record, is constructed using one or more legacy records. For this construction of GRSF records, we apply a set of well-defined rules including rules for merging (use two or more legacy records with "similar" attributes for constructing a single GRSF records), and dissecting (use a single legacy record to construct more than one different GRSF records). All these records (legacy and GRSF records) are then published in VRE catalog, so that: (a) they can be presented in a user-friendly manner, (b) they can be assessed by GRSF administrators, (c) they can be grouped with respect to different criteria. These VRE catalogs, are operated on top of D4Science infrastructure. The VREs that are used for GRSF and their purpose are:
- GRSF Admin VRE: a VRE with restricted access to GRSF Administrators, so that they can assess GRSF records
- GRSF Public VRE: a VRE with public access exposing the contents of the approved GRSF records
- GRSF Pre VRE: a VRE with restricted access to GRSF maintainers, that is used as a staging environment whenever GRSF is being refreshed.
Glossary¶
| Term | Description |
|---|---|
| Legacy Record | The record as it has been derived by transforming its original contents, with respect to the core ontology, For each record harvested from the original sources, we create a single source record and ingest it in GRSF KB |
| GRSF Record | A new record that has been constructed taking information from one or more source records. GRSF records are described in a similar manner with source records (i.e. as ontology-based descriptions), however during their construction they adopt GRSF rules, and use global standard classification as much as possible (e.g. where possible, instead of a species common name use the FAO ASFIS classification), generate new attributes (e.g. semantic ID), flags, citations, etc. |
| Record URI | The identity of a record in GRSF KB in the form of a Uniform Resource Identifier |
| Catalog URL | The URL that is assigned in a record after it is published in the catalog of a VRE. Notice that a record could have more than one different catalog URLs, if it has been published in more than one VRE catalogs (e.g. GRSF Admin and GRSF Public) |
| Source Record URL | The publicly available URL of a record as it appears in the original data source. |
GRSF Construction workflow¶
Here we describe the steps that are followed for constructing GRSF; populating GRSF KB, and publishing the corresponding records in GRSF VREs.
- Harvest data sources: The first step is to fetch data from their original data sources. GRSF does not affect the data from the remote database sources. This means that the maintainers of the database sources will continue to update them in their own systems. For this reason, we have implemented a set of facilities that harvest data from their original sources. As regards FIRMS, we harvest the publicly available factsheets in XML format; harvesting for FIRMS is initiated using a list of valid observation data that includes the appropriate IDs for stocks and fisheries (and their corresponding observation data) that should be fetched. As regards RAM, a dump of the entire database is provided (in MS Access format, which is being "translated" into its XML equivalent. As regards FishSource, we exploit a set of endpoints that have been developed (by the FishSource team) for that particular purpose. The results are retrieved in JSON format and are "translated" into their XML equivalent.
- Define schema mappings: As we described above, GRSF KB is built on top of MarineTLO ontology. For this reason, is is important to describe the mappings between the schemata of the harvested data sources MarineTLO. In order to specify those mappings in a technology-independent manner, we describe them using X3ML mapping specification language. It provides a declarative way of describing schema mappings and the result (the mapping file) can be used for transforming the data.
- Transform harvested sources. This step uses as input the results of the two preceding ones, the harvested data sources and the schema mapping files, and produces ontological instances of the MarineTLO.
- Ingest transformed data to GRSF KB and apply normalizations: During this step the GRSF KB is being populated with the transformed contents. After adding all the resources, several normalization activities occur, to guarantee that the ingested information are valid and complete.
- Construct GRSF records: At this stage, the GRSF KB is being populated with data about stocks and fisheries as they are derived from the original data sources. Using those as input, the construction of GRSF records begins. To construct GRSF Stock records, we apply a merging process that uses as input one or more legacy records if and only if they include the same species and assessment areas. For constructing GRSF Fishery records, we apply a dissection process where one particular legacy record might be able to construct more than one GRSF fishery records, if it (i.e. the legacy record) contains multiple species, or flag states or fishing gears. More detailed information about the merging and dissection process can be found in the GRSF database overview wiki page.
- Identify similarities: After constructing GRSF records, we identify similarities between records, based on their species and the proximity of their areas. At first, we identify the proximity of the areas of all records based on their bounding boxes. The result of this computation is a set of records that have areas either overlapping or adjacent. These result combined with the species or the genus of the species of the corresponding records, enable the identification of similar records. So far we support the following three reasons of similarity: (a) two records have overlapping areas and the same species, (b) two records have adjacent areas and the same species, (c) two records have either overlapping or adjacent areas and the same genus.
- Publish GRSF records in GRSF VREs: The last step of the construction process is to polish all the records (both the legacy and the GRSF ones) in GRSF VREs.
GRSF Refresh workflow¶
Here we describe the steps that are followed for refreshing GRSF. The main difference with respect to the GRSF construction workflow, is that refresh should preserve the publicly assigned URLs of the records (i.e. catalog URLs), as well as any manual updates (e.g. changes in the statues, short names, flags, annotations, manual merges, etc.). So in a nutshell, the refresh workflow should: (a) retrieve the most recent information from the data sources and (b) preserve all aforementioned important information from the current version. The following diagram shows the GRSF refresh workflow.
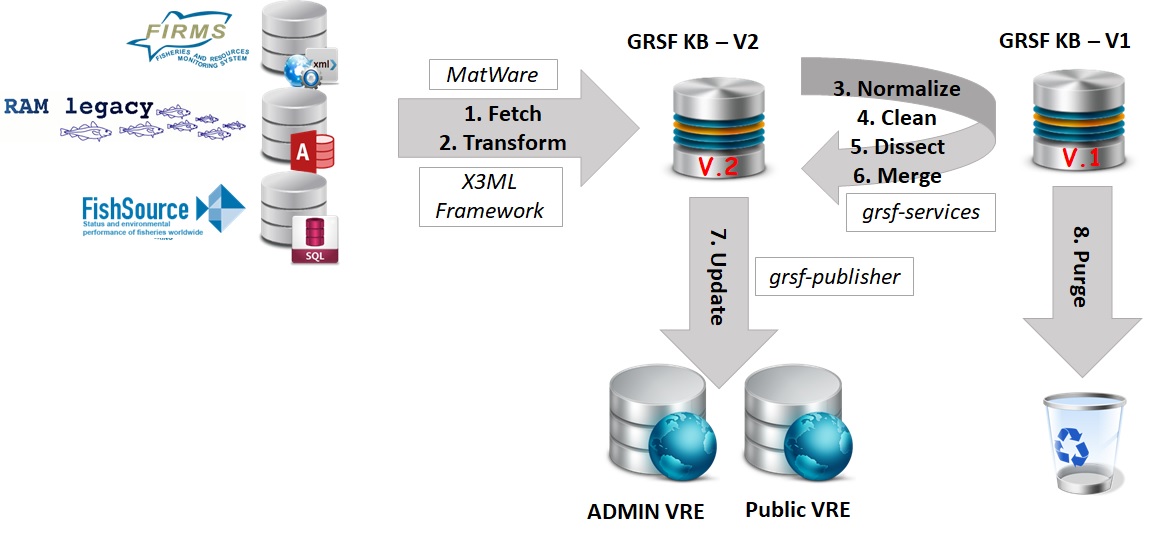
- Export information from the current version of GRSF KB. This is the very first activity that takes place, when GRSF refreshing is triggered. It exports from the GRSF KB, all the information that should be maintained after refreshing GRSF with fresh content from the original data sources. The information that are exported are different for legacy records and GRSF records, and are shown in detail in Preserved Information section.
- Remove records from GRSF VRE catalogs. Both legacy and GRSF records are removed from the GRSF VRE catalogues (Admin and Public). As soon as GRSF KB is refreshed, they fresh records will be re-published in the corresponding catalogs.
- Purge contents from GRSF KB. Remove all the triples from the semantic triplestore that contians the GRSF KB contents.
- Harvest data sources. As described in GRSF construction workflow
- Update schema mappings. This step is only required if the source schemata (e.g. the schemata of the corresponding data sources) have changed since the previous harvesting. If not, this step can be skipped.
- Transform harvested resources. As described in GRSF construction workflow
- Ingest transformed data to GRSF KB using exported information. During this step we ingest the transformed legacy records in GRSF KB. Compared to the ingestion step carried out during the GRSF construction phase, in this step we exploit the information that were exported from GRSF KB, before purging its contents. More specifically, we identify legacy records in the updated version of GRSF KB, using their source URLs. For those that are found, we assign them the corresponding information (e.g. UUID, catalog URL and catalog ID). After that, we will end up with some records with source URLs that are not amongst the exported information. These refer to new records that were not present during the previous harvesting. For those we simply generate a new UUID. On the contrary, we might have a collection of source URLs that existed in the previous version of the GRSF KB, and they can be found within the exported information, but they do not currently exist in the new version of GRSF KB, because they were not harvested (i.e. they do not exist anymore in the data sources). Those legacy records are annotated as obsolete records (a list of obsolete records is constructed as a report for informing GRSF maintainers/administrators).
- Construct GRSF records using exported information. This step is responsible for constructing the GRSF records using as input the legacy records that has been constructed in the previous step. Compared to the corresponding step in the GRSF Construction workflow, in this step, we exploit the information that has been exported from the previous version of the GRSF KB, in order to preserve them after refreshing GRSF. At this point, the process for constructing GRSF Stock records, differs from GRSF Fishery records, mainly because of the merging and dissection processes that are carried out. Particularly, a legacy stock record can be the source of one and only GRSF stock record, while a legacy fishery record can be the source of more than one GRSF Fishery records. The details and pseudo-algorithm for constructing them can be found in GRSF Stock records matching algorithm and GRSF Fishery records matching algorithm
- Identify similarities respectively. As described in GRSF construction workflow
- Publish GRSF records in GRSF VREs. As described in GRSF construction workflow . In addition in this step, we publish all public GRSF records (i.e. those having status approved or archived) in GRSF public VRE.
Preserved Information during GRSF Refresh¶
In this section, we document the information that are exported from GRSF KB, and are preserved when GRSF is refreshed with new (and fresher) content.
Legacy records¶
- source URL: The URL of the record, as it appears in the original data source (e.g. http://firms.fao.org/firms/resource/10089/en,). This attribute is used for identifying each legacy record after fetching fresh content from the original data sources.
- UUID: The unique identifier of the record. This ID has been originally assigned to the record, once it has been added in GRSF KB.
- catalog URL: The URL of the record, as it appears in the GRSF Admin VRE catalog (legacy records do not appear in GRSF Public VRE).
- catalog ID: The ID of the record within the GRSF Admin Vre catalog. Although this ID is not visible to anyone, it is required for updating and deleting a record from the catalog, and as a result, it should be preserved.
GRSF records¶
- UUID: The unique identifier of the record. This ID has been originally assigned to the record, once it has been added in GRSF KB.
- short name: The short and user-friendly name of a record
- status: the status of the record (i.g. pending, approved, archived, etc.)
- semantic ID: The semantic ID of the record. Although it is automatically constructed using the corresponding fields, it is needed for matching GRSF records between different version of GRSF KB. More information about this are given in the next section.
- SDG flag: The SDG flag of the record (i.e. true/false)
- traceability flag: the traceability flag of the record (i.e. true/false)
- source URLs: The URL of the record, as it appears in the original data source (e.g. http://firms.fao.org/firms/resource/10089/en,). This attribute is used for identifying each legacy record after fetching fresh content from the original data sources.
- catalog URL: The URL of the record, as it appears in the GRSF Admin VRE catalog.
- catalog ID: The ID of the record within the GRSF Admin Vre catalog. Although this ID is not visible to anyone, it is required for updating and deleting a record from the catalog, and as a result, it should be preserved.
- *public catalog URL: The URL of the record, as it appears in the GRSF Public VRE catalog. Only records under status approved or archived appear in the GRSF Public VRE catalog.
- public catalog ID: The ID of the record within the GRSF Public Vre catalog. Although this ID is not visible to anyone, it is required for updating and deleting a record from the catalog, and as a result, it should be preserved.
- annotations: Any annotations made by GRSF Administrators.
GRSF Stock records matching algorithm¶
GRSF Stock records follow a merging process when constructed, where records having the exactly the same "key" attributes (i.e. species and assessment areas) are merged into a single one GRSF Stock records. This is a process that can be carried out automatically (i.e. by comparing those attributes during the construction of GRFS), but also manually (i.e. GRSF administrators can propose and implement such mergings after the construction of GRSF). It is evident that although the automatic mergings can be supported when new data sources are fetched, the manual ones cannot be carried out if the corresponding information is not stored and used during refresh. For this reason amongst the information that are exported from the GRSF KB, prior to its refreshment are the merging activities.
The construction of GRSF Stock Records when refreshing GRSF, starts from the information that is exported from GRSF KB before purging its contents. The annotations and methods used in the following algorithm are:
- infoSet: The collection with information exported from the previous version of GRSF KB, and contains these objects.
- record_info: an object of these objects contained in the collection infoset that includes specific information for the record from the previous version of GRSF KB.
- GRSF KB: The new version of GRSF KB, that has been constructed (so far) using fresh contents from the underlying data sources.
- record: a GRSF record constructed in the new version of GRSF KB.
- constructGrsfStockRecord(array[], object): construct a new GRSF Stock record using as source records, the records with the source URLs that are given in the first parameter (i.e. array[]) and preserving all the information that are given in the second parameter (i.e. object)
- addRecordInGrsfKB(record): stores the given GRSF record in GRSF KB
- identifyAsObsoleteRecord: add the given record information object in the list of obsolete records so that GRSF maintainers can further inspect those.
- constructGrsfStockRecords(): construct all GRSF Stock records using all the rules that can be applied using as input the legacy records from GRSF KB.
forall record_info in infoset
if GRSF contains (record_info.source_urls)
record <- constructGrsfStockRecord(record_info.source_urls, record_info);
addRecordInGrsfKB(record)
else
identifyAsObsoleteRecord(record_info)
forall record in constructGrsfStockRecords()
if record not exists in GRSF KB
addRecordInGrsfKB(record)
As is shown above, the algorithm uses two iterations, the first one is used for constructing GRSF records while preserving all their valuable information and identifying obsolete records, while the second one is used for constructing new stock records (e.g. that did not exist in the previous version).
GRSF Fishery records matching algorithm¶
The construction of GRSF Fishery records is different from GRSF Stock records because a different process is followed (i.e. dissection). The annotations and methods used in the following algorithm are:
- infoSet: The collection with information exported from the previous version of GRSF KB, and contains these objects.
- record_info: an object of these objects contained in the collection infoset that includes specific information for the record from the previous version of GRSF KB.
- GRSF KB: The new version of GRSF KB, that has been constructed (so far) using fresh contents from the underlying data sources.
- record: a GRSF record constructed in the new version of GRSF KB.
- addRecordInGrsfKB(record): stores the given GRSF record in GRSF KB
- identifyAsObsoleteRecord: add the given record information object in the list of obsolete records so that GRSF maintainers can further inspect those.
- constructGrsfFisheryRecords(): construct all GRSF Fishery records using all the rules that can be applied using as input the legacy records from GRSF KB.
- updateGrsfFisheryRecord(record,record_info): identifies all the information found in the second parameter (i.e. record_info) in the grsf record that is given in the first parameter.
- partialMatchingSemanticId(id1,id2): identifies if two semantic identifiers match partially. More specifically, it examines if all the mandatory singleton fields in the semantic id are present (e.g. species, flag state, fishing gear), and if the multivalued fields are overlapping (e.g. assessment areas and management units)
forall record in constructGrsfFisheryRecords()
forall record_info in infoset
if record.source_url = record_info.source_url
if partialMatchingSemId(record.semantic_id,record_info.semantic_id)
record <- updateGrsfFisheryRecord(record,record_info)
forall record_info in infoset
if record_info.uuid not in GRSF KB
identifyAsObsoleteRecord(record_info)
The GRSF fishery construction is composed of two iterations; the first one for constructing GRSF fishery records and the second one for identifying obsolete records.
GRSF Inference mechanism¶
This section describes the inference activities that are carried out when constructing GRSF KB, in order to support:
(a) normalization of the data that has been harvested, transformed and ingested from the original data sources,
(b) standardize and present in a uniform manner the information of GRSF records,
(c) facilitate the GRSF merging and dissection processes,
and (d) improve the querying and retrieval of GRSF records using different ways (i.e. GRSF API, GRSF VREs, competency questions, etc.).
GRSF Equivalence rules¶
GRSF Taxnonomic groups mechanism¶
Maintenance diary¶
2020-04¶
- First implementation of GRSF Refreshing workflow
- Harvest data from FIRMS, RAM, FishSource
- Reconstruction of GRSF KB
- Publish records in DORNE VRE and inspection from GRSF Administrators
2020-07¶
- Updates in the GRSF refresh workflow
- Harvest data from FIRMS, RAM, FishSource
- Reconstruction of GRSF KB
- Publish records in GRSF PRE, GRSF Admin, GRSF Public VREs
- Inspection and identification of issues from GRSF Administrators
2020-10¶
- Resolved bugs and issues in GRSF Refresh workflow
- Harvest data from FIRMS, RAM, FishSource
- Reconstruction of GRSF KB
- Identification of obsolete records
- Spotted issues and errors in the original data (as derived from the data sources) using the obsolete records and fixed them where applicable
- Published records in GRSF PRE VRE
2020-11¶
- Harvest data from FIRMS, RAM, FishSource
- Minor update in schema mappings between data source schemata and MarineTLO
- Minor improvements in Transformation of data
- Reconstruction of GRSF KB
- Published records in GRSF Admin, GRSF Public VREs
2021-05¶
- Harvest data from FIRMS (using observation IDs list with date 16Apr2021), RAM (v4.494), FishSource (endpoint v5)
- Manual update of several erroneous scientific names of species coming from FIRMS (e.g. Polyprion spp.).
- Identification of missing scientific names of species from FIRMS (that were afterwards fixed on FIRMS side)
- Proper use of scientific names of species for resources coming from RAM
- Avoid publishing time-dependent information for dissected GRSF records (apply this over GRSF-API as well)
- Identification, and preservation of dominant records for merged GRSF Stock records
2022-05¶
- Harvest data from FIRMS (using observation IDs list with date 18Mar2022), RAM (v4.496), FishSource (endpoint v5)
- First implementation of traceability flags
- Inclusion of vocabularies for species and water areas
Scientific name vs standard codes (ASFIS, WoRMS)¶
Species comparisons to be based on the mapping of FAO 3-Alpha Codes and AphiaIDs instead of on scientific names.
Process:
- Check if the FAO 3-Alpha code matches the 2020 FAO ASFIS classification (http://www.fao.org/fishery/collection/asfis/en).
- Check if the Scientific name of the GRSF record matches the one in FAO ASFIS, if so then create the record. Otherwise, retain the original scientific name or other denomination (e.g. in the GRSF short name) and place the ASFIS matching code and scientific name in the GRSF record (as standard name). In other words, upon checking FAO 3-Alpha codes, give the priority to ASFIS scinames rather than WoRMS.
- FORTH to apply a post-processing step after harvesting and transforming resources from RAM database, with respect to a common vocabulary (the ASFIS list in our case). This will be done during the next harvesting.

