D5.1 Catch-All Notification Broker Back-end: specification and release plan¶
Authors: Claudio Atzori, Miriam Baglioni, Alessia Bardi, Paolo Manghi
- Table of contents
- D5.1 Catch-All Notification Broker Back-end: specification and release plan
Revisions¶
MonthDateComment
M5July 2017First version
M15March 2018
Updates before first BETA release of the service, added sections
Topics in the Literature Broker Service
Notification model extensions
Topics in CAB Service
M23November 2018
Updates after the production release
M23 Updates
Introduction¶
The aim of this document is to present the functional requirements, a specification of the software, and a release plan for the deployment of the OpenAIRE-connect Catch-All Notification Broker Service (referred as CAB Service in the following).
The CAB Service will connect all types of research artefacts providers (institutional repositories, publishers, data repositories, and CRIS systems) and allow them to subscribe and be notified by OpenAIRE of events interesting to them. These notifications will comprise: 1) the existence of artefacts of interest to them (which may pertain their collection) 2) the existence of links from artefacts in their collection to other artefacts. The CAB Service will extend OpenAIRE’s notification brokering services, which serves literature repositories, and will broaden the content provider base with the ones that serve specific research communities.
The CAB Service will be released for testing, assessment, and refinement via a number of Pilots (M11-M20) in two different rounds (at M16 and at M23), to eventually reach a final TRL8 technology level and be released on the OpenAIRE production infrastructure (M28). The resulting web portal will allow content provider managers to register as consumers of the service, set and test the service (preview the results of the service over some subscriptions), to commit their subscriptions, and finally to manage their history of notifications over time.
The CAB will extend the OpenAIRE Literature Broker Service by including all the types of artefacts specified in the OpenAIRE-connect data model D4.1 OpenAIRE Data Model extension.
This deliverable is on-going and will be updated at M15 (before first BETA release of the service), M22 (before second BETA release of the service), and M27 (before production release of the service)
The OpenAIRE Literature Broker Service¶
As described in D4.2 OpenAIRE back-end and Invenio upgrade: specification and release plan OpenAIRE populates an Information Space Graph (ISG) by aggregating information about publications, datasets, organisations, people, projects and several funders collected from hundreds of online data sources. The objects in the graph are harmonised (transformed from their native data model to the OpenAIRE data model) to achieve semantic homogeneity, de-duplicated to avoid ambiguities, and enriched with missing properties and/or relationships thanks to the application of text mining services to the collected publication full-texts. The three infrastructure sub-systems used to harmonise, de-duplicate and enrich the collected data are depicted in Figure 1.

Figure 1. OpenAIRE services high-level architecture
The OpenAIRE Literature Broker Service (OLBS) [1] operates on top of the OpenAIRE information graph and provides repository managers with a Web Dashboard from which they can subscribe to (potential) “enrichment” events occurring to the graph and of interest to their repository. Whenever a new information space is generated, the OLBS explores the graph to detect if any of the active subscriptions find a match and in such case notifications are generated, delivered, and archived.
Figure 2 shows how the OLBS integrates with the existing OpenAIRE infrastructure.
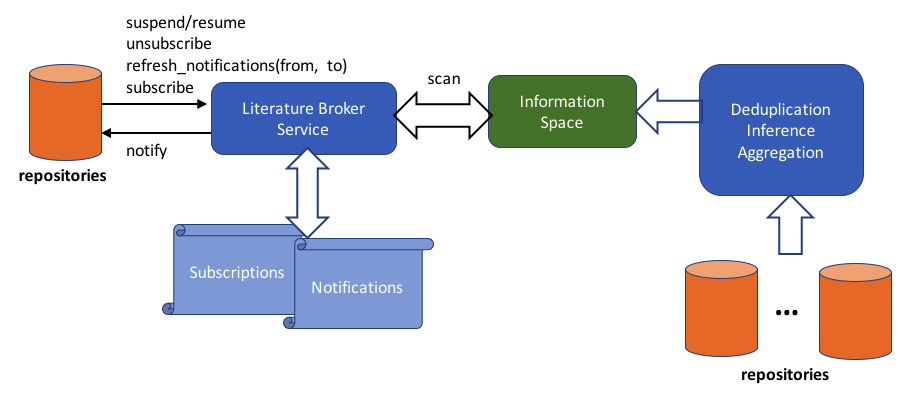
Figure 2. OLBS in the OpenAIRE infrastructure
Subscriptions¶
Repository managers can subscribe to Enrichment events that can be defined as:
Enrichment events identify objects fed by the repository to OpenAIRE that have been enriched by OpenAIRE inference algorithms or de-duplication merges. Repository managers will be able to fine-tune their subscriptions based on the bibliographic fields they would like to be notified about; e.g. “return the fields DOIs and Funding Project relative to my records”.
Examples¶
Two macro-categories of topics are provided by OpenAIRE as consequence of the enrichment processes that contribute to improve the IGS quality. When subscribing, a publication field must be specified to select the specific kind of events the subscriber is interested to.
ENRICH / MISSING is a macro-category that groups events about publication field values that are not present in the metadata of the repository. For example, a repository manager subscribing to the topic ENRICH / MISSING / ABSTRACT will be notified when an abstract is found for the publications in his/her repository which do not have an abstract in their associated metadata.
ENRICH / MORE is a macro-category that groups events about publication field values that differ from those available in the repository. In this case an event is generated when the publication metadata does not have a value for the given field (like in the previous macro-category) or when the publication metadata has a value for the field that differs from the value available, for the same publications, from another repository. For example, a repository manager subscribing to the topic ENRICH / MORE / OPENACCESS_VERSION will be notified about Open Access versions of publications that are not already present in his/her repository.
Notifications¶
Two different notification strategies are under evaluation in order to meet diverse requirements of subscribers:
- Mail postcards Subscribers may opt to be notified by email at given interval of times (e.g. daily, weekly, monthly) and with given granularity (individual records, digests, URL to a web user interface).
- Programmatic access:
- Pull mode: APIs will be provided to retrieve notifications by status (e.g. read/unread), subscription typology, and filters (e.g. criteria on the metadata fields).
- Push mode: webhooks and the SWORD [2] protocol for automatic ingestion of records into repositories will be evaluated.
Architecture overview¶
The OpenAIRE information space graph (ISG) is stored in an HBASE cluster in order to support performance and scalability. The collected metadata record, transformed into objects compliant to the OpenAIRE data model, are then stored into HBASE, where each record corresponds to one HBASE row. Once populated, the HBASE table is ready to be processed by inference and de-duplication algorithms for enrichment. The OLBS will have to further process the OpenAIRE ISG to identify addition and enrichment events to be notified to subscribers. The OLBS integration in the OpenAIRE infrastructure is shown in Figure 3, and it is composed by three phases:
- Phase1: generation of events A Map Reduce job will be executed on HBASE whenever a new version of the ISG is generated with the aim of finding events, i.e. all the modification for enrichment present in the graph with respect to the original version as it was collected from data providers. The events will be stored in an Elasticsearch index.
- Phase2: subscription matching the OLBS queries the index generated in the previous phase to search for the events that match the existing subscriptions (which are stored in a Postgres database).
- Phase3: find new events In this phase, from the events selected in phase2, those that have not already been notified to the repository manager are selected, sent to the repository manager, and eventually stored in the Elasticsearch index under the notification entry.
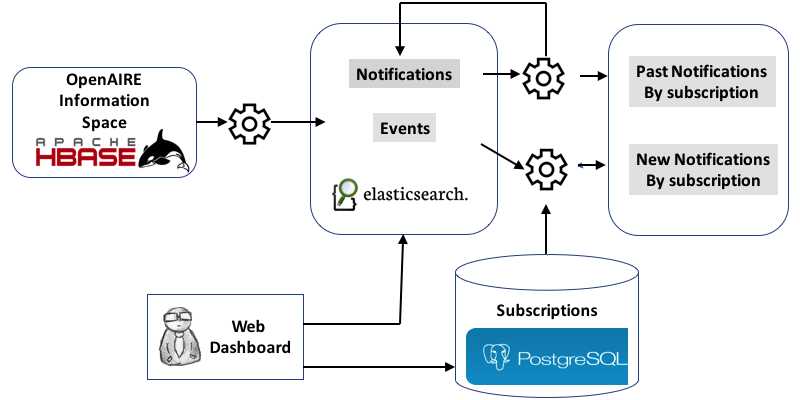
Figure 3. OLB Data Flow
Topics in the Literature Broker Service¶
The Literature Broker Service (LBS) developed in the context of the OpenAIRE2020 project provides a set of TOPICS that users (repository managers) can subscribe to, in order to be notified about valuable information to be integrated in their metadata collections. The available topics are presented in the following table.
TopicActionDescription
ENRICH/MORE/OPENACCESS_VERSIONEnrich with more Open Access versionsOpenAIRE discovered another Open Access version of a publication
ENRICH/MORE/PIDEnrich with more persistent identifiersOpenAIRE discovered another persistent identifier associated to your publications
ENRICH/MORE/SUBJECT/MESHEUROPMCEnrich with more MeSH classification termsOpenAIRE discovered more classification terms from the Medical Subject Headings (MeSH) that can be associated to your publications
ENRICH/MORE/SUBJECT/DDCEnrich with more DDC classification termsOpenAIRE discovered more Dewey Decimal classification terms (DDC) that can be associated to your publications
ENRICH/MORE/SUBJECT/ACMEnrich with more ACM classification termsOpenAIRE discovered more ACM classification terms that can be associated to your publications
ENRICH/MORE/SUBJECT/JELEnrich with more JEL classification termsOpenAIRE discovered more Journal of Economic Literature (JEL) classification terms that can be associated to your publications
ENRICH/MORE/SUBJECT/ARXIVEnrich with more ARXIV classification termsOpenAIRE discovered more ARXIV classification terms that can be associated to your publications
ENRICH/MISSING/PIDEnrich with persistent identifiersOpenAIRE discovered missing persistent identifiers associated to your publications
ENRICH/MISSING/PROJECTEnrich with project referencesOpenAIRE discovered references to research projects that can be associated to your publications
ENRICH/MISSING/ABSTRACTEnrich with publication abstractsOpenAIRE discovered missing abstracts among your publications
ENRICH/MISSING/SUBJECT/MESHEUROPMCEnrich with MeSH classification termsOpenAIRE discovered classification terms from the Medical Subject Headings (MeSH) that can be associated to your publications
ENRICH/MISSING/SUBJECT/DDCEnrich with DDC classification termsOpenAIRE discovered Dewey Decimal classification terms (DDC) that can be associated to your publications
ENRICH/MISSING/SUBJECT/ACMEnrich with ACM classification termsOpenAIRE discovered ACM classification terms that can be associated to your publications
ENRICH/MISSING/SUBJECT/JELEnrich with JEL classification termsOpenAIRE discovered Journal of Economic Literature (JEL) classification terms that can be associated to your publications
ENRICH/MISSING/SUBJECT/ARXIVEnrich with ARXIV classification termsOpenAIRE discovered ARXIV classification terms that can be associated to your publications
ENRICH/MISSING/PUBLICATION_DATEEnrich with date of publicationOpenAIRE discovered missing date of publication among your content
ENRICH/MISSING/OPENACCESS_VERSIONEnrich with Open Access versionsOpenAIRE discovered Open Access versions of your publications
The latest analysis of the OpenAIRE information space from the beta environment produced the following set of events
Topic
Count
ENRICH/MISSING/PID
18.269.728
ENRICH/MORE/OPENACCESS_VERSION
11.191.592
ENRICH/MORE/PID
6.250.075
ENRICH/MORE/SUBJECT/JEL
2.627.334
ENRICH/MISSING/SUBJECT/JEL
793.035
ENRICH/MORE/SUBJECT/DDC
450.292
ENRICH/MISSING/ABSTRACT
440.679
ENRICH/MORE/SUBJECT/MESHEUROPMC
164.561
ENRICH/MORE/SUBJECT/ARXIV
140.142
ENRICH/MISSING/SUBJECT/DDC
127.119
ENRICH/MORE/SUBJECT/ACM
126.193
ENRICH/MISSING/PROJECT
88.369
ENRICH/MISSING/PUBLICATION_DATE
44.660
ENRICH/MISSING/SUBJECT/ACM
42.624
ENRICH/MISSING/SUBJECT/MESHEUROPMC
38.161
ENRICH/MISSING/SUBJECT/ARXIV
30.017
ENRICH/MISSING/OPENACCESS_VERSION
12.012
ENRICH/MORE/SUBJECT/RVK
914
ENRICH/MISSING/SUBJECT/RVK
52
Towards the CAB Service¶
The OpenAIRE Literature Broker Service (OLBS) was designed to support repository managers, allowing them to benefit from the value added by the OpenAIRE services (mining, de-duplication) to the information space graph. The work of repository managers is focused on the curation and quality of their publication collections, but growing interest in research data opens the door to newer use cases. The CAB service widens the use case of the OLBS by extending it to analyse and generate events relative not only to publications, but also to other types of objects of the research life cycle included in the OpenAIRE-Connect data model: datasets, research methods, and research packages.The CAB Service will include the Enrichment functionality as exposed by the OLBS, and it will provide also two more functionalities, namely Additions and Alerts. These functionalities will operate on a bigger set of research artefacts.
The two new functionalities are defined as follows:
Addition events identify objects that enter into the OpenAIRE information space graph, are not present in the repository, but may be part of its collection. The identification of these events requires the navigation of the Information Space graph, in an attempt to identify relationships between the subscribing institutional repositories (which are a specific OpenAIRE data source type) and publications that have not been collected from the given repository but are “relevant to” it. The main difference with the Enrich events is that the Addition events do not merely update the metadata of publications already present in the provider collection, but they enlarge the provider collection with new publications
Alerts events identify errors of the data and/or of the relationship. They can be split in three categories:
- users: this kind of alerts are produced by the claiming service through users feedback. The alerts will be notified to the repository manager and eventually to the source of the alert.
- completeness: this kind of alerts are produced by the transformator service and will be related to the completeness of the ingested data (i.e. missing publication title),
- compatibility: this kind of alerts are produced by the validator service and will be related to the compliance to the OpenAIRE Guidelines (see https://guidelines.openaire.eu).
Contrary to enrichments and additions, alerts do not suggest the integration of information that can enhance the provider collection, but rather inform the repository manager that the quality of metadata should be improved. Furthermore, repository managers subscribed to alert events will be notified as soon as the event is dispatched by the CAB service. In case of completeness and compatibility alerts, the CAB service will notify a report produced for the repository using the information provided by the transformation or the validator services.
Examples of the functionalities provided by the CAB Service¶
Addition¶
Relationships: publication - author - repository
A possible criterion, to detect which publications may be "relevant to" a repository, could be based on the relationships authorship, i.e. the publication has an author, and authorRepositoryOfReference, the author deposits her publication in the given repository. Authorship is generally provided by the collected metadata, while authorRepositoryOfReference needs to be inferred by OpenAIRE services. To this aim, the services should exploit the results of the de-duplication algorithms over authors and publications.
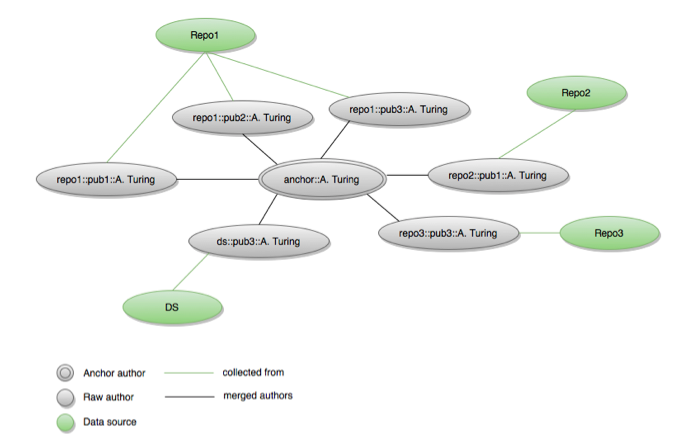
Figure 4. Affiliation detection: using de-duplication to compute the closeness of an author to a repository
Accordingly, with a given degree of approximation, when OpenAIRE collects a new publication from a given repository it will be possible to state if some of its authors have a different repository of reference. An exemplification is shown in Figure 4. The same author string ("A. Turing") collected from four different data sources (three institutional repositories and one data source of a different typology) results in four different person objects. When the de-duplication is run, the four persons are merged into one new "anchor" object ("anchor::A. Turing", in the example). As first instance of the association, the repository most frequently referred to by an author for submission will be considered as the repository of reference for that author. Once determined that, for example, "Repo1" is the repository of reference for an author, it may be interested in being notified about the publications the same author deposited in "Repo2", "Repo3" and "DS".
In order to avoid redundant notifications, publication de-duplication will be used to understand whether the repository of reference already has the publications or should be notified.
Alerts¶
In case of alerts produced from user feedback, these typically involve relationships produced by the inference system. Such systems can infer erroneous relationships, therefore OpenAIRE includes a mechanism that allows users to provide feedback about such errors (blacklist service). In these cases, the notification could be sent to the user responsible for the Inference System that produced an erroneous inferred link related to the alert, other than the repository manager.
Subscription related to alerts will be specified in a format compatible with the enrichment events. Examples of alert subscriptions can be: ALERT / USER that is all the alerts related to the repository, coming from users should be notified, or ALERT / COMPLETENESS that is: produce reports on alerts associated to Completeness events.
CAB Event Payload¶
The OLBS Data Model, shown in Figure 5, will remain essentially unchanged. The Repository class will contain information on the repository and the specification of the constraints an event must satisfy to be notified, whereas the Subscription configuration class will contian the notification options. The Potential notification and Notification classes contain information pertinent only to publications : title, authors, publication date, and DCRecord. Similar information to enable search and browse must be defined also for the other kinds of entities. For datasets, for example, we can inherit a subset of the fields defined in the DataCite format.
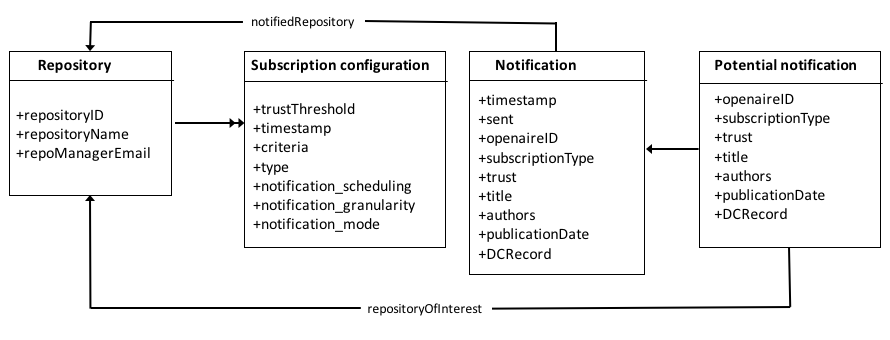
Figure 5. OLBS Data Model
Notification model extensions¶
In order to represent events about datasets, software and products, the CAB notification model is updated based on the specification of the OpenAIRE guidelines:
- OpenAIRE Guidelines for Data Archives (to be updated to adopt the latest version of the Datacite schema in the context of the OpenAIRE-Advance project).
- OpenAIRE Guidelines for Software Repository Managers
- OpenAIRE Guidelines for Other Research Products (ORP) Repository Managers
More details will be added to this section when the guidelines will be finalised. At time of writing, the status of the guidelines is the following:
- Dataset: upgrading to Datacite schema 4.1 ongoing
- Software: guidelines under review by international software initiatives
- ORP: guidelines under review by partners of the OpenAIRE-Connect consortium.
Topics in CAB Service¶
The CAB service was released in M21. Topics related not only to literature objects were devised thanks to the analysis of the ScholExplorer knowledge graph. In fact, Scholexplorer aggregates relationships between Literature and Dataset objects, making it possible to derive added value information for the data archive managers. To this aim, dedicated components were introduced in the ScholExplorer workflows to periodically generate events. The topics summary is presented in the following table.
TopicActionDescription
ENRICH/MISSING/DATASET/IS_REFERENCED_BYEnrich with dataset referencesOpenAIRE discovered a dataset referenced by your record
ENRICH/MISSING/PUBLICATION/IS_RELATED_TOEnrich with publication referencesOpenAIRE discovered a publication related to your record
ENRICH/MISSING/PUBLICATION/REFERENCESEnrich with publication referencesOpenAIRE discovered a publication referenced by your record
ENRICH/MISSING/PUBLICATION/IS_SUPPLEMENTED_TOEnrich with supplementary publicationOpenAIRE discovered a publication that supplements your record
ENRICH/MISSING/DATASET/IS_RELATED_TOEnrich with dataset referenceOpenAIRE discovered a dataset related to your record
ENRICH/MISSING/PUBLICATION/IS_REFERENCED_BYEnrich with publication referencesOpenAIRE discovered a publication that refers to your record
ENRICH/MISSING/DATASET/REFERENCESEnrich with dataset referencesOpenAIRE discovered a dataset that refers to your record
ENRICH/MISSING/PUBLICATION/IS_SUPPLEMENTED_BYEnrich with supplementary publicationOpenAIRE discovered a publication that is supplemented by your record
ENRICH/MISSING/DATASET/IS_SUPPLEMENTED_TOEnrich with supplementary datasetOpenAIRE discovered a dataset that supplements your record
ENRICH/MISSING/DATASET/IS_SUPPLEMENTED_BYEnrich with supplementary datasetOpenAIRE discovered a dataset that is supplemented by your record
ENRICH/MISSING/SOFTWAREEnrich with references to research softwareOpenAIRE discovered references to research software that can be associated to your publications
ENRICH/MORE/SOFTWAREEnrich with references to research softwareOpenAIRE discovered references to research software that can be associated to your publications
ALERT/STALE/ACCESSRIGHTSInform about an outdated access rightsOpenAIRE discovered that a publication in your repository is no longer under embargo and thus can be marked as Open Access
ALERT/MISSING/TITLEInform about the missing publication titleOpenAIRE discovered that a publication in your repository does not provide any title
Links to Datasets¶
The OpenAIRE Information Space contains links between Publications and Datasets. Such links indicate relationships belonging to different semantics and are produced by two subsystems:
- Metadata aggregator: collects and harmonise bibliographic records on publication and dataset, mapping the semantic relationships among such entities in the ISG;
- Information Inference system (IIS): by analysing the publication full-text files the IIS creates relationships among publications and datasets.
In order to produce valuable notifications is it crucial to preserve the provenance of the relationships produced by such subsystems. In fact the same relationship could be mapped from the original bibliographic records, as well as inferred from the publication's full-text. In such case, the notification would not contribute with any novel information to the repository that provided the publication. For this reason the relationship encoding in the OpenAIRE ISG must support multiple provenance information.
Instead in ScholExplorer, relationships between objects were modelled considering multiple provenance information upfront. This allows to distinguish the different contributors supplementing an entity with links towards datasets, publications, etc. To derive the added value and build the broker events, the analysis of the ScholExplorer information space is based on the connected components of duplicate objects (cc) built by the deduplication process. For each cc the analysis procedure can identify, thanks to the multiple provenance data found in each link, the information missing in each contributor.
Links to Software¶
In most publications research software does not emerge as first level citizen, as it is rarely deposited in repositories that gives persistent identifiers (DOIs) allowing for proper citation. Unlike data repositories, software repositories usually do not assign persistent identifiers and literature products usually refer to software via URL. Thanks to the OpenAIRE inference subsystem, the such URL are resolved and Software entities are created in the Information Space, together with a link to the publication. This enables the possibility to define a TOPIC in the CAB Service relative to the relationships that OpenAIRE infers between Publication and Software.
Release plan¶
The CAB Service will be released for testing, assessment, and refinement via a number of Pilots (M11-M20) in two different rounds (at M16 and at M23), to eventually reach a final TRL8 technology level and be released on the OpenAIRE production infrastructure (M28).
The release plan can be summarised as follows:
M15 - beta 1
This release will include the extension of the back-ends to support the entity types in the OpenAIRE-Connect data model, i.e. the events and the relative payload definition will reflect the new entity types.
M22 - beta 2
A minimal set of objects for each new entity will be deposited in the system or harvested via Zenodo, and an extended set of topics will be available for testing.
M28 - production
The introduction of new entity types (especially datasets) will constitute a significant growth in the number of objects involved in the data flow described in Figure 3. Such growth, estimated in 20% per year, will be faced with the addition of new resources on the different back-ends: new Elasticsearch nodes, new worker nodes on the Hadoop cluster.
M23 Updates¶
Below the updates introduced in the development of the CAB service since November 2018 - M23.
According to the release plan the CAB Service should have been deployed in the production infrastructure by M28. However, its deployment was anticipated to M21 to better support the pilot activities with relevant content. In fact beta and production environments are based on two independent aggregation systems, each comprising different data sources and content, with the latter including more than the first. As the focus was moved from the beta to the production environment, the resources allocated on the beta backend services (especially Elasticsearch) were redirected to support the development activities, freeing more resources for the production system.
The creation of events relative to the presence of novel links between Literature and Dataset objects was delegated to the OpenAIRE satellite initiative ScholExplorer, whose focus is the aggregation of relationships between Literature and Dataset. By analysing the ScholExplorer knowledge graph it was possible to devise the topics of interest for Data archive managers described in the Topics in CAB Service section.
The growing interest for initiatives that maintain persistent identifiers for different stakeholders that spin around the research objects lifecycle sees an important player in ORCID, an initiative that assigns persistent identifiers to researchers. The availability of PIDs for publication authors is still limited and doesn't reach many repositories, thus this poses the base for the definition of a topic that supports repository managers in discovering such information. The topic is defined according to the table below and the creation of new events is under testing in the beta environment, in fact it includes data sources providing enough test cases supporting the creation of events for this topic. The early results will be then included in the assessment activities planned in the pilots.
The creation of events relative to the topic ALERT/STALE/ACCESSRIGHTS, i.e. aiming at informing repository managers about the end of the embargo period, was dropped from the implementation plan because the OpenAIRE aggregator takes care of changing the access rights status to OPEN in records whose embargo period is over during the metadata transformation phase. Thus, as the broker service analyses the information space in a subsequent phase it would not find relevant information to generate such event.
The creation of events relative to the topic ALERT/MISSING/TITLE, i.e. aiming at informing repository managers about result objects lacking the title, was dropped from the implementation plan because the OpenAIRE aggregator already skips records that do not contain the title during the transformation phase, considering them as not compliant with the OpenAIRE guidelines. Therefore, as the broker service analyses the information space in a subsequent phase it would not find relevant information to generate such event.
TopicActionDescription
ENRICH/MISSING/AUTHOR/ORCIDEnrich with author persistent identifiersOpenAIRE discovered one of your publication that includes authors identified with ORCID
References¶
- Artini, M., Atzori, C., Bardi, A., La Bruzzo, S., Manghi, P., & Mannocci, A. (2015). The OpenAIRE Literature Broker Service for Institutional Repositories. D-Lib Magazine, 21(11/12).
- Lewis, S., de Castro, P., & Jones, R. (2012). SWORD: Facilitating deposit scenarios. D-Lib Magazine, 18(1), 4. http://doi.org/10.1045/january2012-lewis

