D4.3 Configurable mining algorithms: specification and release plan¶
Authors: Natalia Manola (ARC), Harry Dimitropoulos (ARC), Yannis Foufoulas (ARC), Tasos Giannakopoulos (ARC)
1. Introduction¶
This is the final version of the document whose aim is to present a specification of the software and a release plan to consolidate configurable mining algorithms at TRL8. These algorithms mine full-texts to identify links between literature and research initiatives. The interactive platform for configuring mining algorithms is presented in the following sections of this document.
The main updates compared to the previous version of this deliverable are the following:
- Enhancement of the interface for notifying the mining team that a new or updated mining profile has been saved
- The UI has been upgraded to Angular 7. The UI is presented in section 2.3
- The interface had become more user-friendly according to the feedback received
- Reported bugs have been fixed and some general optimizations have been made
- More file formats for user testing are now supported
2. Interactive mining platform¶
The interactive mining platform is a platform for configuring text mining algorithms. The purpose of these algorithms is to identify links from literature to research initiatives. The platform allows users to customize mining algorithms and run them on their test datasets.
The interactive mining platform is up and running as part of the research community dashboard and its user interface is accessible at https://beta.admin.connect.openaire.eu/mining/manage-profiles
The produced algorithms can be integrated within the IIS as described below:
- The research initiative manager defines mining rules and tests them using sample sets of articles.
- The research initiative manager requests for deployment in beta.
- The OpenAIRE Mining Team (OMT) reviews the mining configuration and proposes possible improvements.
- OMT deploys the configuration for beta and asks the research initiative manager to check the results on the beta portal.
- The research initiative manager defines more or different mining rules if the results can be further improved, or else s/he requests for deployment in production.
The architecture and the user interface of the application are presented below.
2.1 Architecture of the Interactive Mining Platform¶
Figure 1 shows the architecture of the platform. The backend of the platform is developed using Python’s Tornado Web Server [1]. Tornado is a Python web framework and asynchronous networking library. By using non-blocking network I/O, Tornado can scale to tens of thousands of open connections, making it ideal for long polling, WebSockets, and other applications that require a long-lived connection to each user.
MadIS [2] is the processing engine of the platform. It is an extensible relational database system built on top of the SQLite database with extensions implemented in Python. MadIS has rich support for arbitrary user-defined functions (UDFs) written in the Python language (and already includes a large collection of functions for data/text mining, data cleaning, stream processing and more).
There are three different kinds of UDFs supported by madIS:
- Virtual table functions: Their output is indistinguishable from a regular table as far as the rest of the query is concerned.
- Row functions: They run once per row of the input table, and they may produce multiple rows (and multiple columns, per its output schema).
- Aggregate functions: They provide alternatives to standard SQL aggregation, i.e., collapsing multiple rows into one.
These features allow the implementation of mining algorithms completely within madIS. MadIS is open source and available at https://github.com/madgik/madis. Its documentation is accessible at http://madgik.github.io/madis.
There is a REST API on top of the backend for the communication with the front-end. The front-end of the application is developed using Angular 7 typescript framework.
The user of the interactive mining platform selects and configures the mining rules which are sent via the REST API to the backend. Then, they are translated into a madIS SQL query that consists of plain SQL and Python UDFs. The translation is done by the Tornado Web Server which is connected directly with the madIS database.
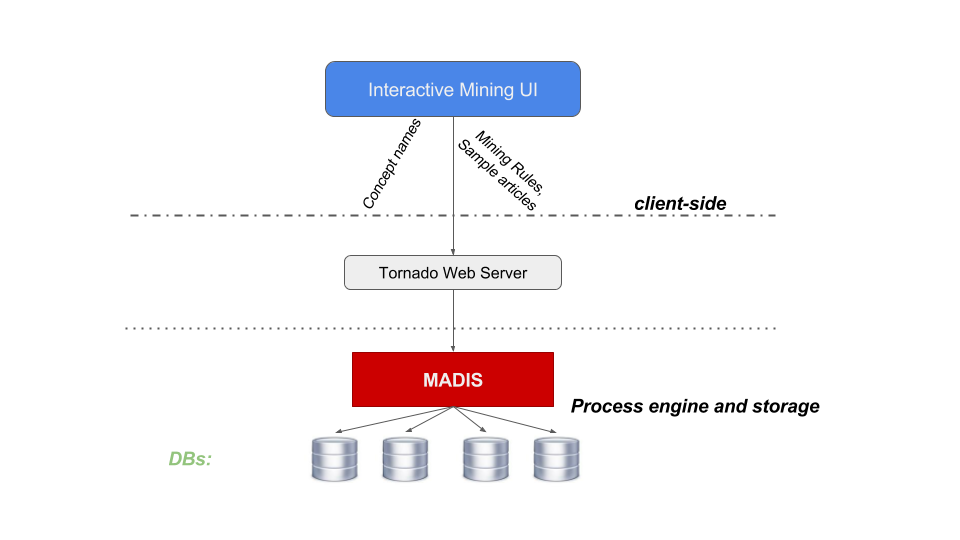
Figure 1. Architecture of the interactive mining platform
The query runs against a test dataset, which is uploaded by the user, and the mining results are presented by the interface of the platform.
The following section presents the functionalities of the interactive mining platform.
2.2 Functionalities and New Features¶
The user is able to configure text extraction algorithms. The implemented algorithms text mine publications’ full-texts and extract links to research initiatives based on relevant concepts (e.g., thematic, regional, virtual organisations) and projects.
The user is able to upload a list of concept names, set the mining rules, preprocess the publications’ full-texts with several steps and get the results.
The preprocessed full-text is matched against the list of concepts. The mining rules regard the selection of weighted positive and negative phrases. These phrases are pattern matched against the text near an extracted concept and define if it’s a true match or a false positive. The user is also able to upload specific acknowledgement statements for each concept individually. These statements are also used as positive patterns.
Several new features have been added until now:
- Support for regular expressions The user adds his suggested phrases for each concept. These may be not only simple text but fully functional regular expressions. Possible security threats like SQL injection have been addressed.
- Specify the search area Statistical algorithms have been implemented to extract sections from the text like the references section or the acknowledgement section. The user selects the section in which s/he wishes to search for the concepts.
- Administrator panel The administrator of the system may view all profiles, evaluate them and accept them for beta integration.
The following section presents with screenshots the steps that a user has to follow in order to configure a research initiative mining algorithm.
2.3 User Interface¶
The User Interface (UI) has been redesigned from scratch in order to be user-friendlier, and allow users to define even complex mining procedures. The UI was designed using online Mock-up tools and after receiving feedback from users.
The new user interface with the new functionalities is presented in the next pages of this deliverable using screenshots.
Figure 2 presents the user’s home page. Here users are able to see their saved profiles, create new profiles, or edit the existing ones.
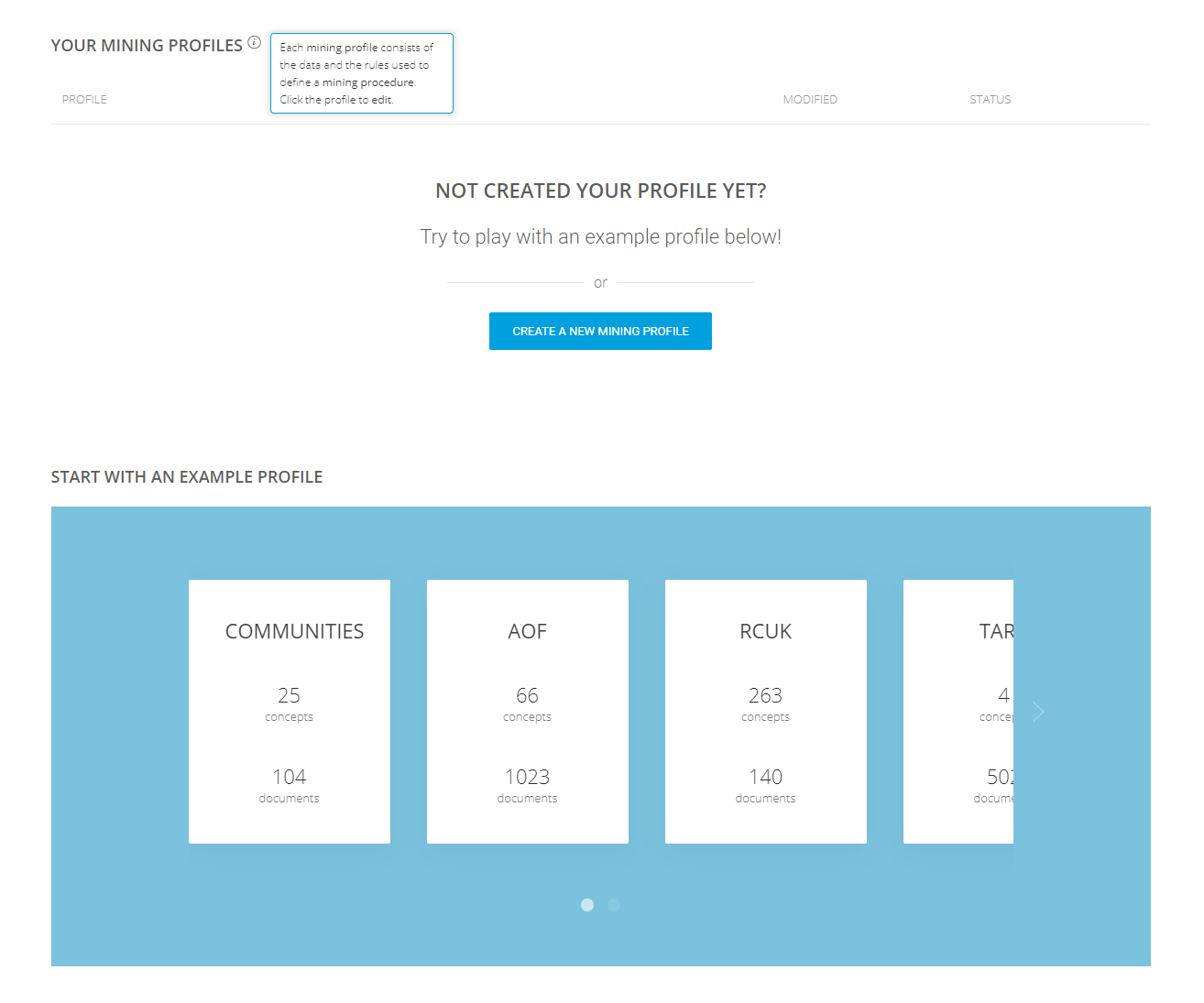
Figure 2. Home page of the interactive mining platform
After selecting/creating a mining profile, users are able to configure their algorithm. The first step regards the addition/deletion of mining concepts. Users can either use the online form to edit their concepts or drag and drop a tabular file.
Figures 3 and 4 illustrate how users can upload and edit their concepts. Users can use acknowledgement statements or other key phrases that may contain regular expressions.
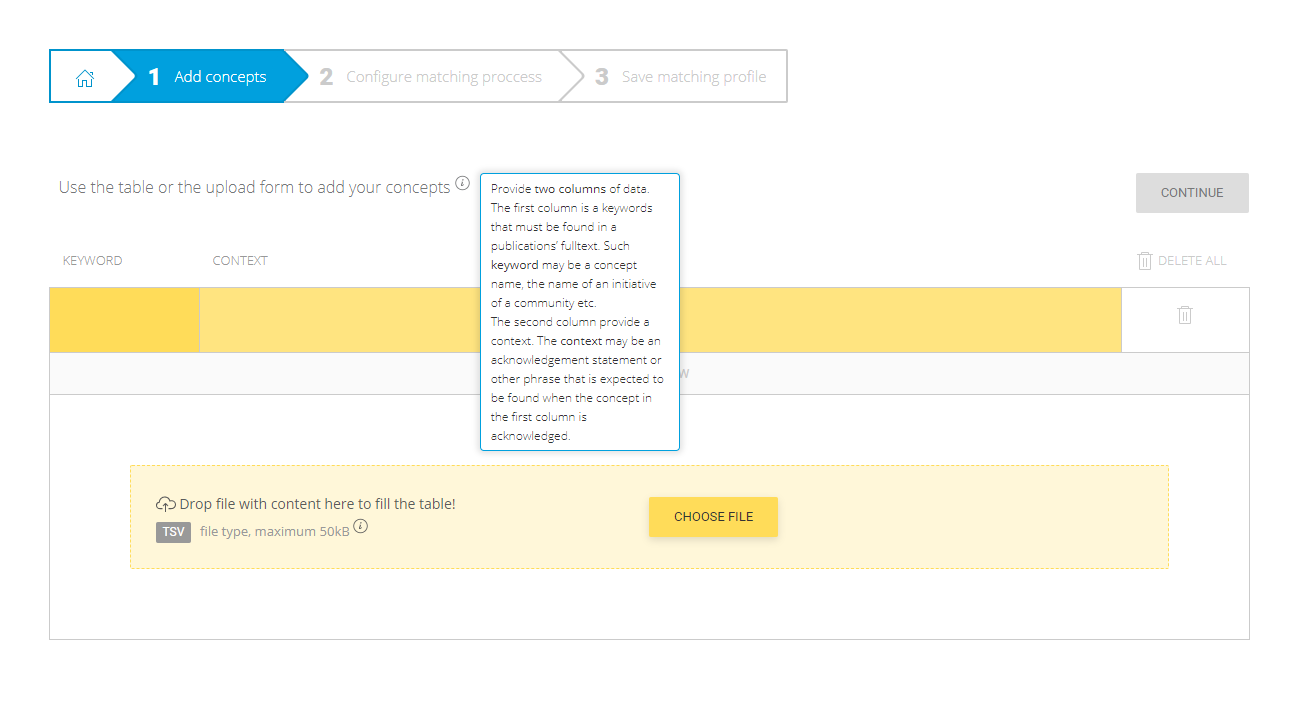
Figure 3. Upload concept names/acknowledgement statements form

Figure 4. Edit concept names/acknowledgement statements form
When the concepts are ready, users are able to configure their mining rules. They can define their mining strategy, add positive/negative phrases/keywords, and tune the preprocessing steps.
The page shown in Figure 5 is the page where users set their rules.
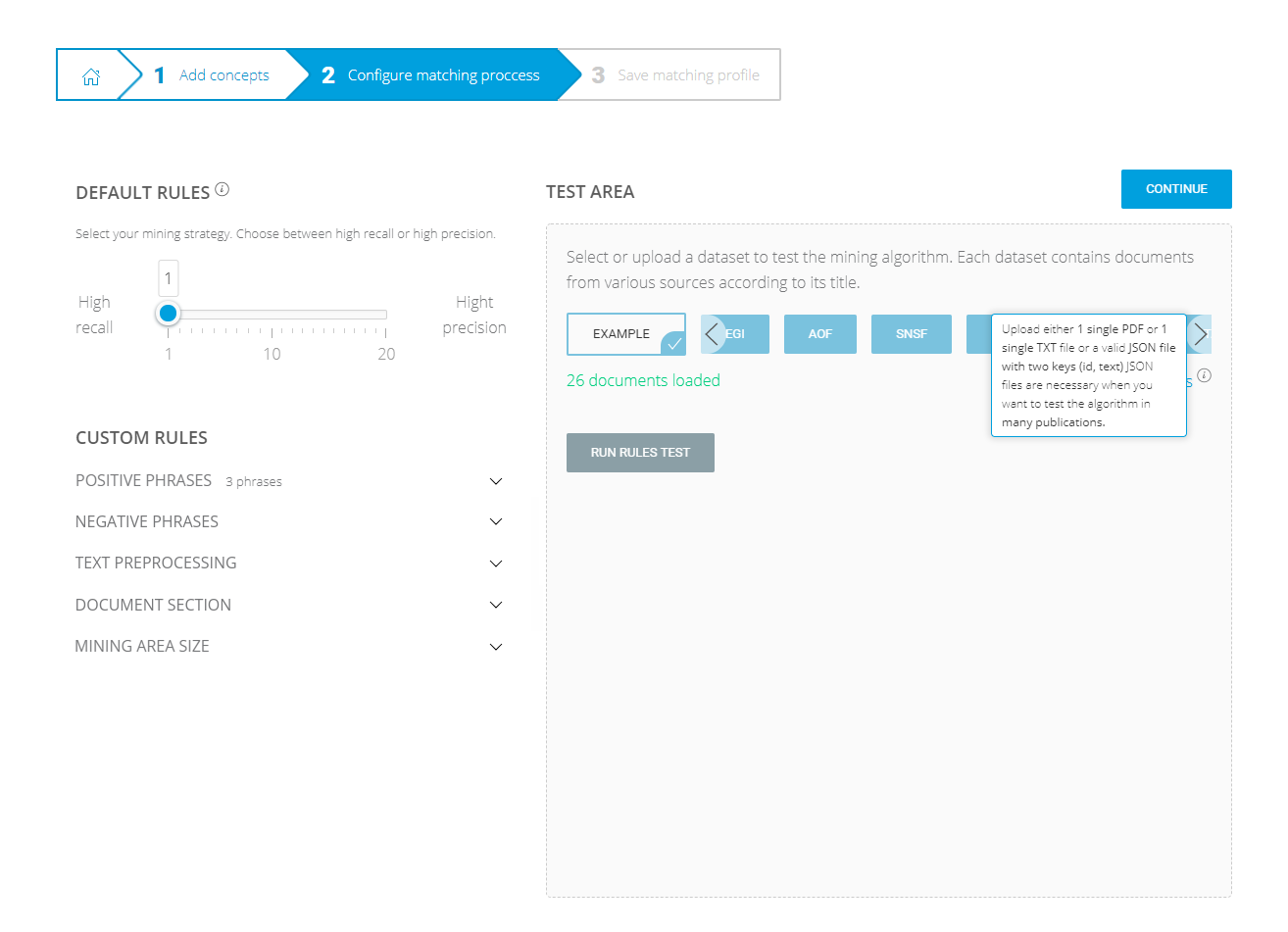
Figure 5. Mining configuration
Figure 6 shows how the platform runs the algorithm against the selected datasets. The mining results are presented using annotated text. Users may also select the document section where the mining algorithm will be applied (full body, acknowledgement section, citations).

Figure 6. Mining Results
Figure 7 regards the last step of the mining configuration. Users can save their configuration for future use. As shown in Figure 8, when logged in again, users can see their saved profile at his home page.
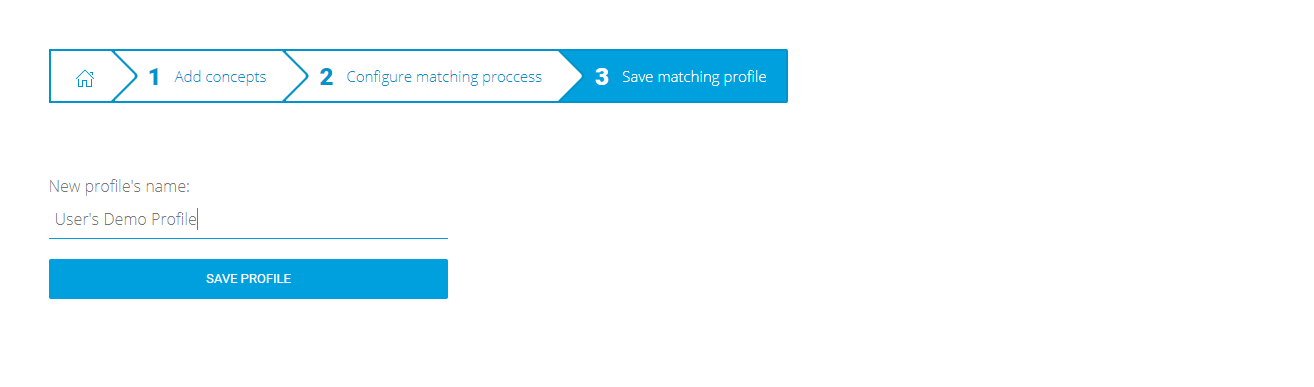
Figure 7. Save mining profile
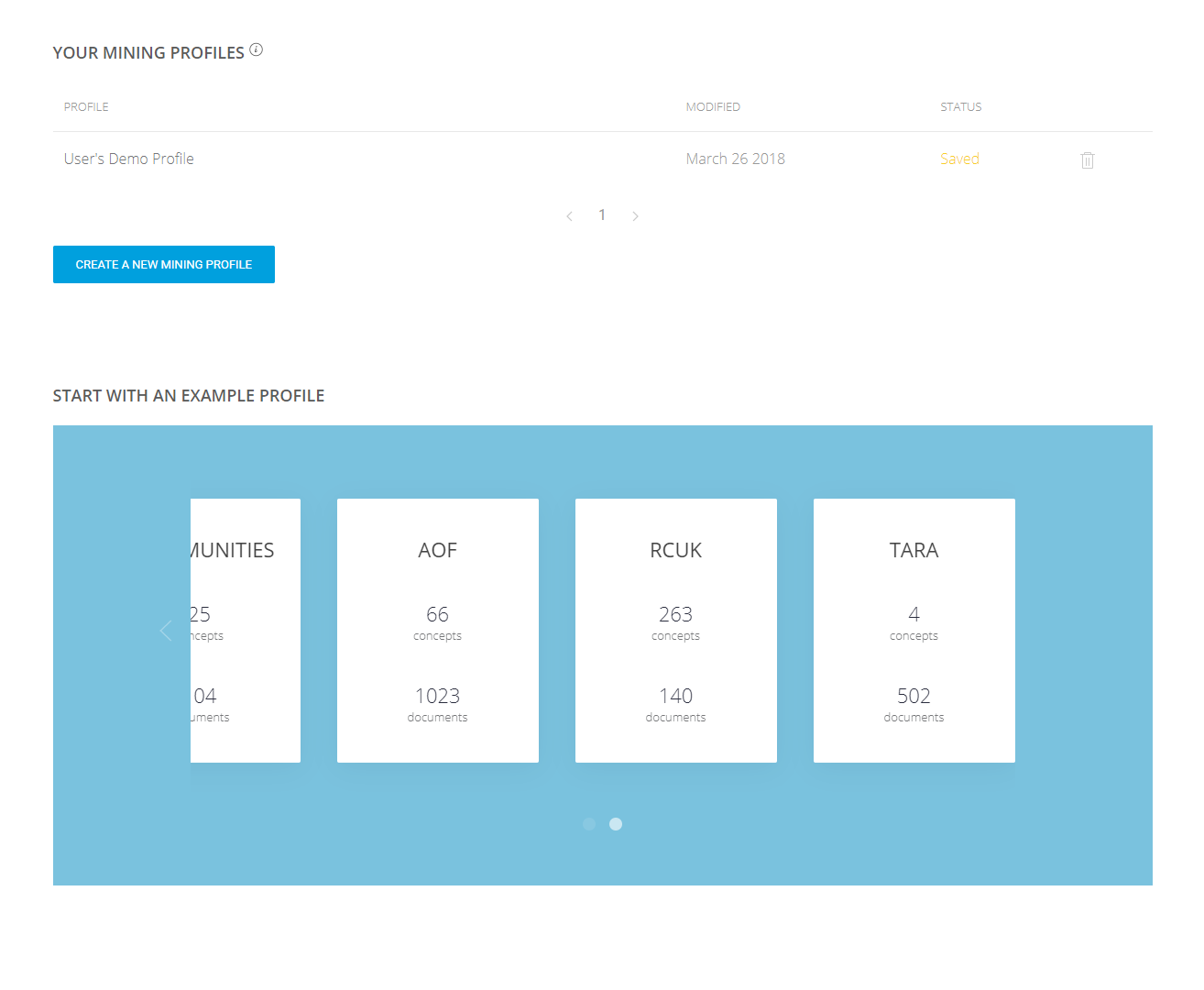
Figure 8. User's home page with saved mining profiles
Figure 9 shows the recent addition of the "NOTIFY" button that can be used to notify the OMT when a mining profile is ready to be processed. In other words, when a user decides that his/her mining profile is final and ready to be published, using the notify button, an email is sent to mining@openaire.eu that alerts the OMT that there is a new or updated mining profile from a research initiative. The OMT will then review the mining configuration and either propose possible improvements or proceed with deployment.
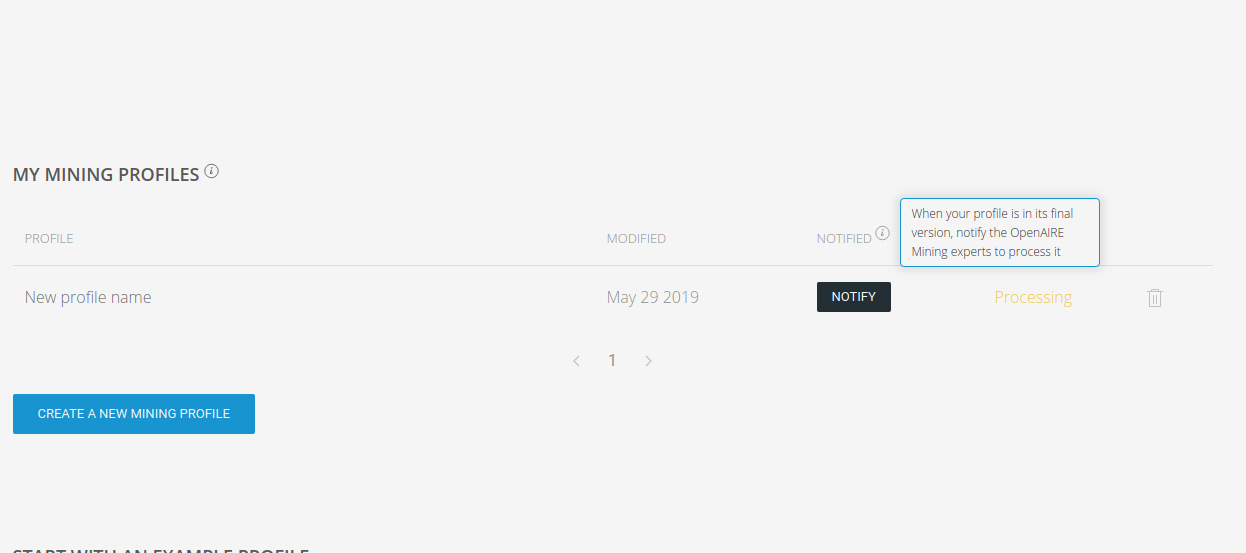
Figure 9. Notify button
Figure 10 presents the administration interface. The administrator views a list with all the submitted mining algorithms, their current status, and may evaluate them and submit them for beta integration.

Figure 10. Administration interface
3. Release Plan¶
The integration in the OpenAIRE research initiative dashboard is done.
The M27 update was the final update under the OpenAIRE-Connect project and included some general optimizations and minor interface updates, the fixing of a couple of bugs reported (mainly for UI issues with different web browsers), and the support of more file formats for user testing. The research initiative dashboard will continue to be supported and further developed under the OpenAIRE-Advance project.
However, the two most important changes for the final update were (1) the UI's upgrade to Angular 7, and (2) the enhancement of the interface for notifying the OMT that a new or updated mining profile has been saved ("notify" button), as presented in section 2.3.
3.1 Release Process¶
The interactive mining platform is deployed often and early to ensure high speed in delivering new features/bug fixes.
- Regular deployment: By default, the platform is regularly deployed every two weeks containing new features and/or bug fixes.
- Hotfix deployment: Hotfixes should be made immediately and deployed depending on urgency.
3.2 References¶
[1] Dory, Michael, Allison Parrish, and Brendan Berg. Introduction to Tornado: Modern Web Applications with Python. " O'Reilly Media, Inc.", 2012.
[2] Giannakopoulos, Theodoros, et al. "Content visualization of scientific corpora using an extensible relational database implementation." International Conference on Theory and Practice of Digital Libraries. Springer International Publishing, 2013.

